pandas数据处理 |
您所在的位置:网站首页 › pandas 行处理 › pandas数据处理 |
pandas数据处理
|
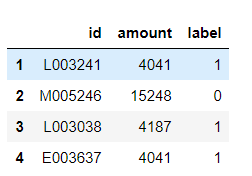
平常我们用pandas做重复数据处理时,常常调用到drop_duplicates方法来去除重。 现在我不想完全去除重复,而是把重复数据输出,现有数据如下所示:
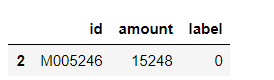
重复数据保留一个,duplicate_bool输出的是bool类型值,通过判断bool==True,取出重复行。 duplicate_bool = df.duplicated(subset=['id'], keep='first') repeat=df.loc[duplicate_bool == True] repeat输出:
采用drop_duplicates对数据去两次重,一次将重复数据全部去除(keep=False),一次将重复数据保留一个(keep=last/first),将两个去重后的数据做差集,取出重复行。 # 重复数据全部去除 data1= df.drop_duplicates(subset=['id'], keep=False) data1输出:
输出:
输出:
|



【本文地址】
今日新闻 |
推荐新闻 |